Winter Research
A lot of data nowadays is stored online or in the ‘cloud’, separating clients and servers by kilometres upon kilometres of distance. The client moves their data to a server with more memory and speed to be able to compute things in the cloud at rates faster than they could ever do so by themselves. The client storing the data on the server has to be able to trust the server and that the server is uncompromised in order to keep their information secure. Ways in which this can be done will be discussed in this post.
Back in December I have worked as a URA for Assistant Professor Sergey Gorbunov of University of Waterloo in the area of secure storage of information in the cloud. The task was to measure and evaluate different techniques commonly used in cloud based storage as well as to explore the emerging field of searchable symmetric encryption.
The model used for testing is a very simple client-server model. The server stores many text files and provides clients with the ability to search/query the files containing requested words/phrase. Here is an illustration below (figure 1):
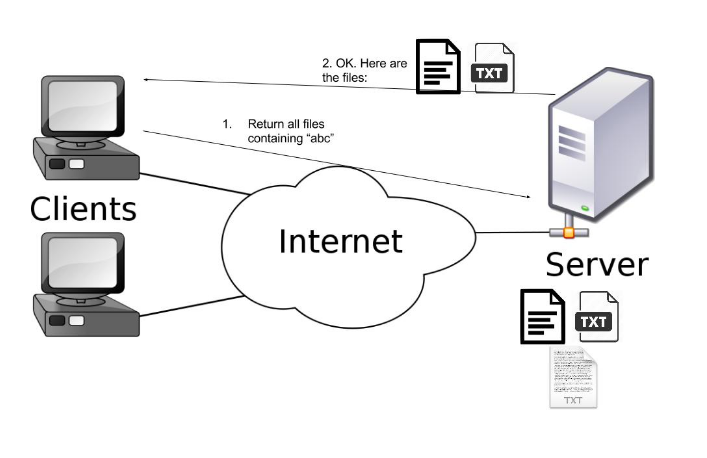
There were two techniques tested in the model. The first involved simply storing the data on server without any modification (same as in the picture above) whereas the second approach involved storing the files in an encrypted format. An encrypted file was a mapping of the original text file where every word was individually encrypted using the same key with preserved order overall. Here is an illustration of a mapping (figure 2):
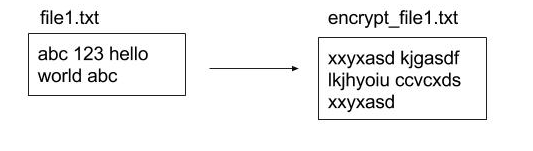
The encryption in the example above was completely made up by me to help explain the file transformation (we can discuss the actual encryption details a little later). However, one thing I do want the reader to observe in my made up example is that “abc” recorded twice in file1.txt gets mapped on to “xxyxasd” twice with the order preserved. In fact, all the files stored on server are encrypted in such a way that “abc” in file1 and file2 would map to “xxyxasd” in encrypt_file1 and encrypt_file2 in the same order that they originally appeared.
Now that we have our encrypted files stored on server, how do we execute search as shown in figure 1?
Since we only have the encrypted files stored on server we can’t search for “abc” on the server directly anymore since it has “xxyxasd” in its original place. Hence we have to be able to encrypt our search word in advance before sending it to the server. Our encrypted client-server model now looks something like this when searching for “abc” (figure 3):
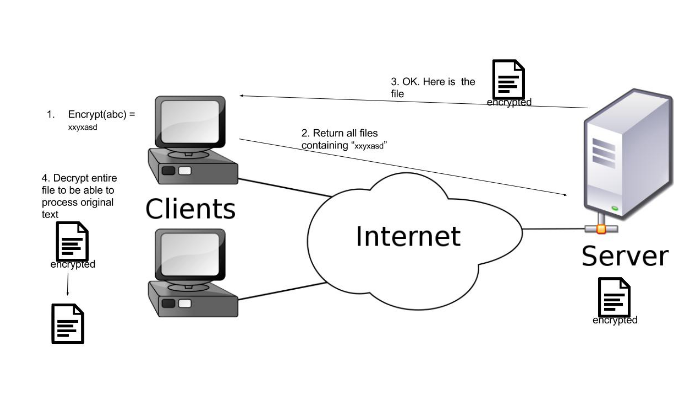
The actual encryption used in my model was AES - ECB mode where a given plaintext is divided into blocks and each block is encrypted individually.
Comparing the techniques at a glance
The first technique is the simplest as it does not change the original data. Anyone with this information can easily read and interpret it. The downside is that the files stored on the server are stored in an unencrypted format meaning that anyone with access to the server can view the data. The intended users of the server have to be confident in the security of the server.
The second technique is the encrypted format. The data on the server cannot be easily read and interpreted but involves more time in initial encryption setup as well as decryption upon data retrieval. From this setup we can already get a sense that there is a little more work involved in handling the data.
Comparing the techniques with an experiment
I went on to set up the two techniques in order to be able to compare the two to each other. Here are the details:
The server-client in the project was to model a health info-patient setup. 16.5MB worth of formatted health related 2270 articles from Wikipedia were downloaded and stored on the server using Elasticsearch. In addition, 1197 health related queries were sourced from the AOL leak for use by the client.
The client would send the queries, to the server (ran on uwaterloo server) to then receive the top 20 matches of articles (if there were any). The queries would return the documents that contained the individual words that best matched the query. The search algorithm on the server/Elasticsearch provided a degree of approximation to the words/phrases to accommodate for spelling mistakes and over-specific queries (similar to what google search does). In the case of encryption, the Wikipedia articles were first encrypted before being stored on server and the queries from client were first encrypted before sent on to the server.
Further details on implementation can be found here: https://github.com/mannyray/es_basic_encryption
Comparing the numbers
The initial Wikipedia articles were 16.5 MB in size, which when encrypted, inflated to about 85MB. The expansion of data was expected as the string ‘a’ could end up being encrypted into ‘0x731b31922c9228465e0f0ea51ea7f’ (hex format). This humble sample size was used to get a basic comparison and understanding of the two methods of data storage.
Accuracy
Some queries were expected to be unmatched since the queries could have been too specific or out of range for the limited data present in database. After storing the data on Elasticsearch and querying the results for regular storage the server was able to match for 42% of the time and for the encrypted 34% of the time. The discrepancy was expected since it is impossible to approximate spelling with encrypted words. Further analysis of the mismatch proved this theory showing that only 0.25% queries were matched only for encrypted(not regular) and 7.6% only for regular.
Query time
The query time on Elasticsearch was much greater for the encrypted version. In fact, 79% were faster for regular text and an additional 5% were slower for regular only because encrypted could not match anything at all while regular could. The average query time for regular was 2.64ms and 6ms for encrypted. Here is a cdf of the times (blue for regular and red for encrypted ~ showing that regular has the speed advantage) where x is time in milliseconds:
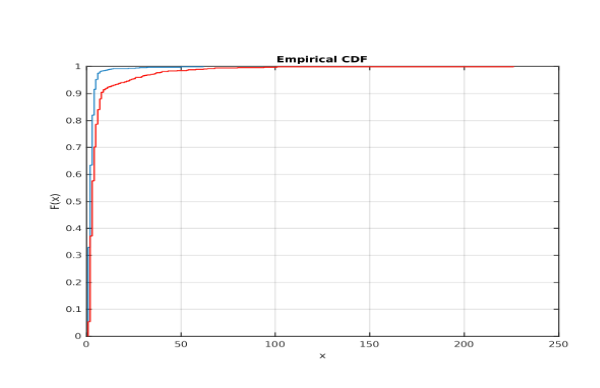
The regular (blue) technique can be observed to be much faster than encrypted version.
Discussion
Both methods of storing data, encrypted vs unencrypted, each have their respective benefits and drawbacks in the categories of speed, security and usability.
Speed:
Speed is a major concern when storing/retrieving data. For a large company with many servers and many clients, good speed would be crucial in running a successful operation. With encryption we saw a significant slowdown in search time as well as a significant inflation in data size. In a real life situation this would translate to more memory expense and time to execute queries.
The unencrypted format is compact and fast. It would not require the data to be encrypted ahead of time for storage or decryption upon data retrieval from server, saving even more time overall.
Security:
There is no doubt that unecrypted is insecure. It has to be to stored in a safe location or deemed to be safe for everyone to see. However, ‘stored in a safe location’ can go wrong, as seen in the BC data leak and the AOL leak (used in this experiment).
The encrypted version in this scenario encrypts every word individually before storing the documents. Unfortunately, this is only slightly more secure than the unecrypted version since the encrypted version is susceptible to a frequency analysis (one of the oldest decryption attacks). For example, if one of our encrypted files has ‘0x872343…..a98’ as the most frequent word then we can take an educated guess and say that this matches with the word ‘the’ (a very frequent English word) and continue working this way until we have cracked the overall text to a meaningful message.
A potential fix to this: the encrypted version would have had to change the encryption of identical words by using a counter to incorporate into the IV of AES encryption which would make all version of the same encrypted word different. This would make it secure from frequency analysis but would greatly increase search time overall as you now have to search for all versions of the encrypted word (and know how many there are in advance).
Usability:
Finally, usability is also an issue when it comes to data storage. It is the most easiest to store and use the data in an unecrypted format. Whereas the encrypted format is very rigid and hard to analyse as was shown in the accuracy section previously. The speed also plays a role in usability where the encrypted speed is very unattractive.
Conclusion
To conclude it is worth to say that both encrypted and unecrypted formats have their advantages and disadvantages as this experiment was able to show. Encrypted provides more security while unecrypted provides ease and speed of use. A perfect blend of both is desirable to provide the best of both worlds to the user. One of the areas of research covering this blend is searchable symmetric encryption (sse). Techniques in sse protect the data from the unwanted eye but give the ability of more ease of search for the intended user. The area of research is relatively new and is growing rapidly with lots of information online for the curious reader.